Hi there!
I'm a second year PhD student at UC San Diego in the Center for Visual Computing, advised by Prof. Tzu-Mao Li and Prof. Ravi Ramamoorthi. My research interests are in improving light transport algorithms for forward and inverse rendering, and exploring their applications. At the moment, I'm particularly interested in exploring various problems in differentiable and inverse rendering, as well as efficient sampling and denoising methods for real-time rendering. I'm also interested in GPUs and have written plenty of other software.
I received my BASc in Computer Engineering at UBC, where I worked remotely with Prof. Toshiya Hachisuka and Prof. Derek Nowrouzezahrai on efficient sampling for real-time rendering. I also worked with Prof. Tor Aamodt on improving ray tracing acceleration on GPUs.
In my free time, I enjoy cooking dishes from all around the world.
Feel free to send me an email if you'd like to chat!
Recent Publications

Parameter-space ReSTIR for Differentiable and Inverse Rendering
Wesley Chang, Venkataram Sivaram, Derek Nowrouzezahrai, Toshiya Hachisuka, Ravi Ramamoorthi, and Tzu-Mao Li
SIGGRAPH North America 2023 (Conference Track)
Physically-based inverse rendering algorithms that utilize differentiable rendering typically use gradient descent to optimize for scene parameters such as materials and lighting. We observe that the scene often changes slowly from frame to frame during optimization, similar to animation, and therefore adapt temporal reuse from ReSTIR to reuse samples across gradient iterations and accelerate inverse rendering.
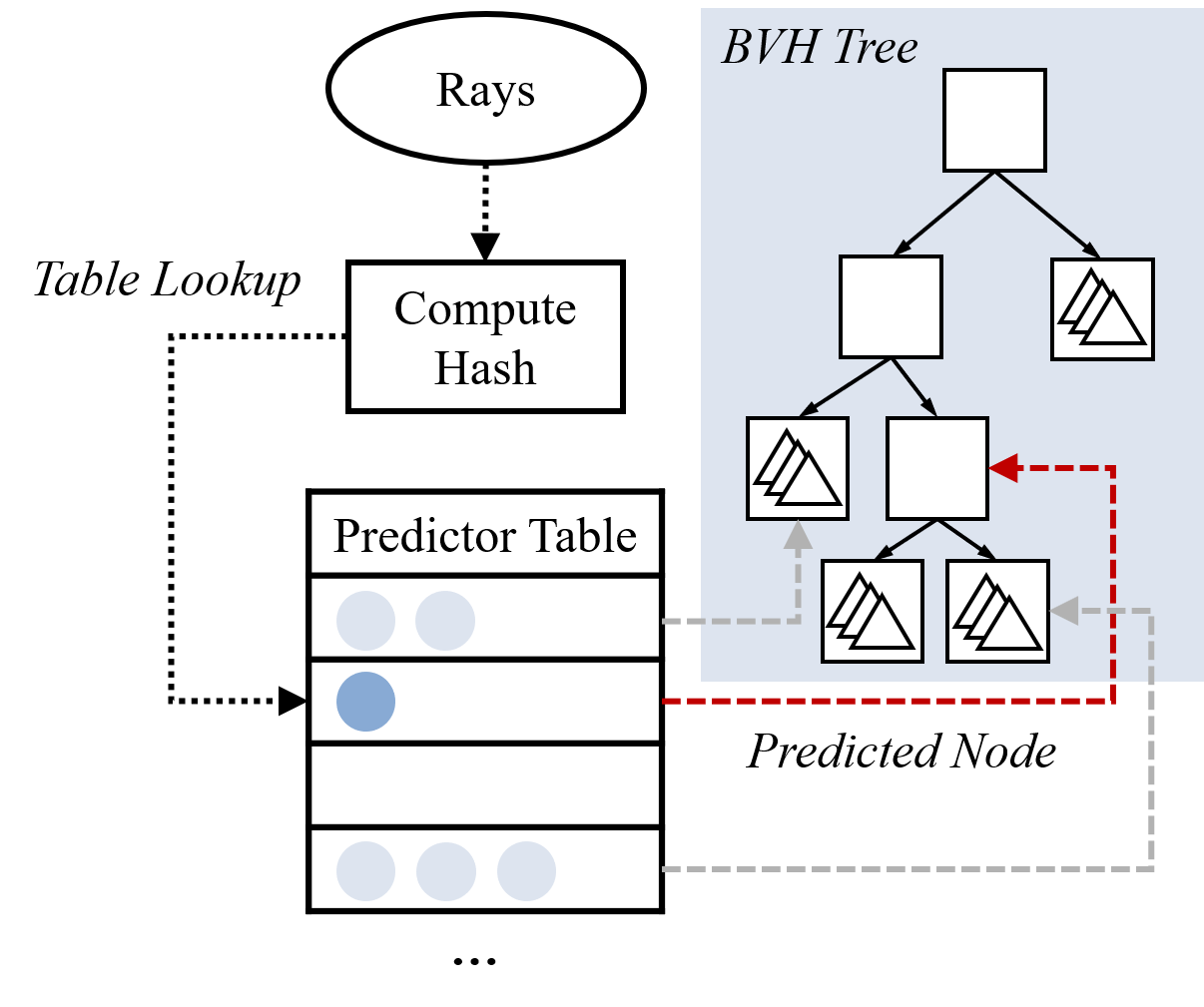
Intersection Prediction for Accelerated GPU Ray Tracing
Lufei Liu, Wesley Chang, Francois Demoullin, Yuan Hsi Chou, Mohammadreza Saed, David Pankratz, Tyler Nowicki, and Tor M. Aamodt
54th IEEE/ACM International Symposium on Microarchitecture (MICRO), 2021
Recent Graphics Processing Units (GPUs) incorporate hardware accelerator units designed for ray tracing. These accelerator units target the process of traversing hierarchical tree data structures used to test for ray-object intersections. We propose a ray intersection predictor that speculatively elides redundant operations during this process and proceeds directly to test primitives that the ray is likely to intersect.